
来源:Python绿色通道
ID:
Python_channel
作者:龙哥带你飞
背景
做自媒体的人,尤其是做了一年甚至更久的自媒体人,尤其是通过自媒体还有一些小收入的人,他们最怕自己的公众号内容因为各种原因而丢失,那就太可怕了! 在做自媒体内容上花了太多心血,如果突然一下就没了,那打击是相当大的,所以备份好自己的成果是非常重要的.
像我之前没有这方面意识,最近我做了一个小工具,把公众号文章打包成pdf文件,然后保存到本地,免去后顾之忧.
其实我之前写过了相关的文章,但那个时候写的还不是很好,不算完美,因为打包出来的文件,看不到图片,所以一直觉得有瑕疵!
最近我终于把这个瑕疵给解决了, 另外再解决了其它的几个问题,算是比较完美的升级吧!
先看效果图:

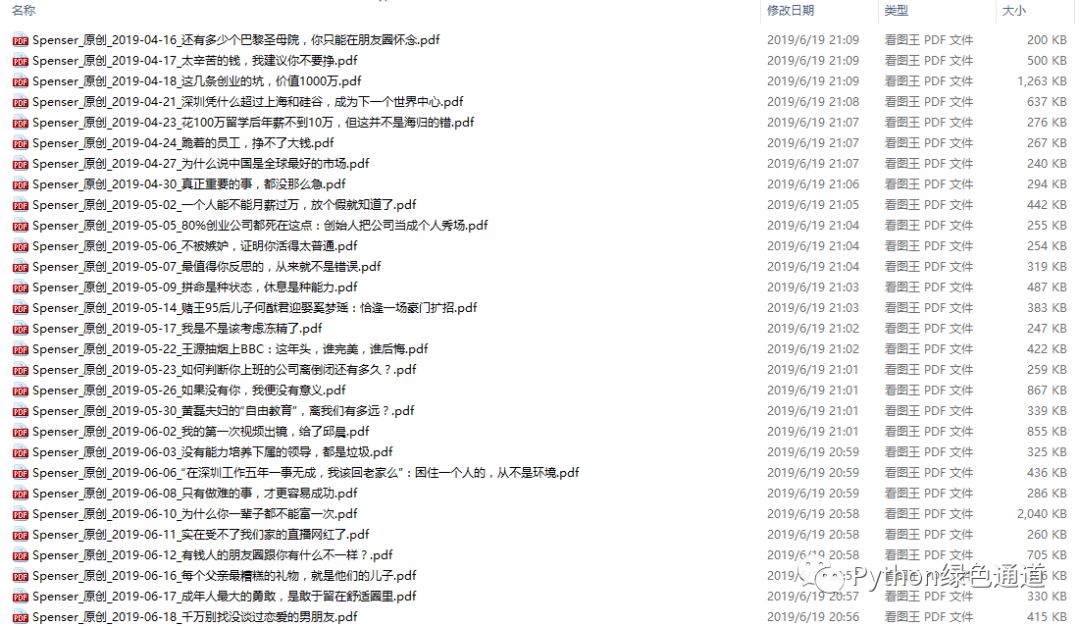
有目录,有图片。
解决图片显示问题,先看生成的pdf文件样子
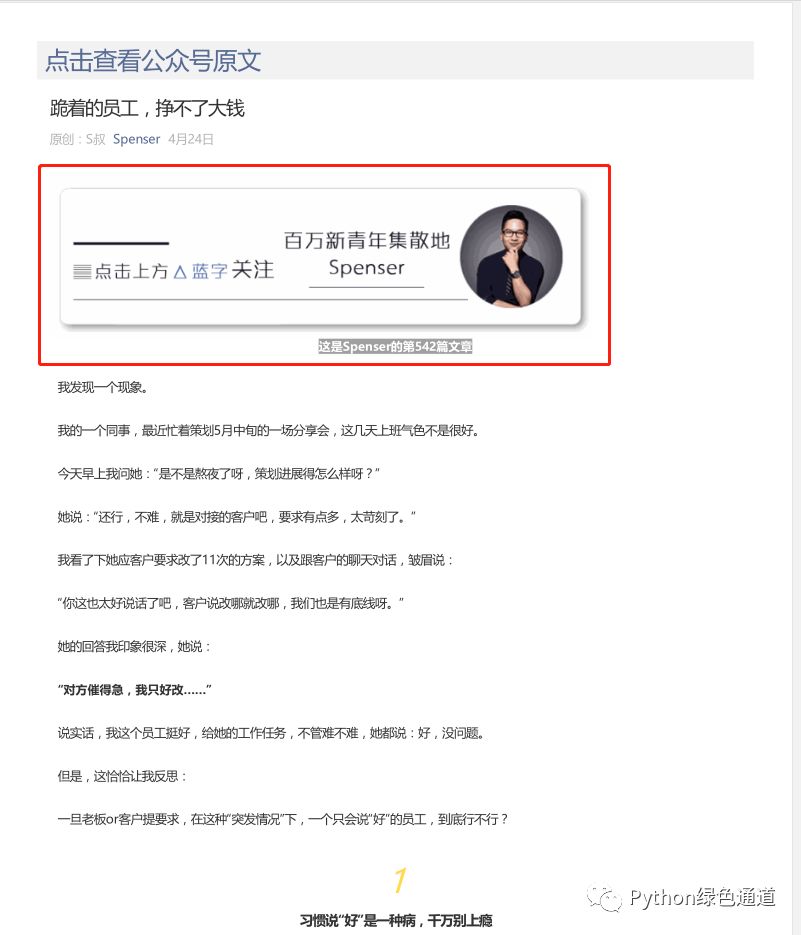
其实直接获取到公众号文章的url就可以通过pdfkit工具包来生成一个pdf文件,但是这样获取出来的pdf文件图片是显示不出来的。
因为公众号文章里的图片是用src来标记的,这在pdf中是不能显示图片,所以我在这里把,src替换成了src,然后图片就可以显示出来.
def create_article_content(self, url, text): """文章内容""" str = '点击查看公众号原文'.format( url) + text.replace('src', 'src') return str
这部分代码的含义: url 是公众号原文链接,text 是公众号网页内容这里面包含了样式.
因为我把内容抓取过来后,我还想去点击原文,所以有了这个超链接,像上面图片中的【点击查看公众号原文】,再看看如何生成pdf文件.
生成pdf文件
单篇文章生成一个文件
每篇文章就是一个文件,但这种生成文件的方式比较慢,好处就是每篇文章单独成一个文件. 看效果图:
具体代码如下:
def creat_pdf_file(self, title, html_content): html = 'tmp.html' # 这里是存放临时html文件with open(html, 'w', encoding='utf-8') as f: # 点击open函数查看用法,这里是写入不要搞错了 f.write(html_content)
try: output_file = 'D:/gzh2/{}.pdf'.format(title)if not os.path.exists(output_file): # 过滤掉重复文件 pdfkit.from_file(html, output_file, configuration=self.config, ) # 注意这里需要配置一下wkhtmltopdfexcept Exception as e: print(sys._getframe().f_code.co_name) print(e)finally: os.remove(html)
title是文件名, html_content是文件内容,这里把文件内容定稿到一个临时的html文件中,然后把这个临时的html文件用pdfkit工具转换成pdf文件.
所有文章生成一个文件
这里是把所有的html文件内容组成一个数组,然后把这些内容列表转换成html的文件列表,然后把html文件列表放到pdfkit中转换成一个pdf文件,这个好处就是比较快速,但是所有的文件都放到一个文件中,感觉不利于阅读,也看各人喜好吧,效果图如下:
看代码
def creat_pdf_file(self): htmls = []for index, file in enumerate(self.html_contents): html = '{}.html'.format(index) # 这里是存放临时html文件 with open(html, 'w', encoding='utf-8') as f: # 点击open函数查看用法,这里是写入不要搞错了 f.write(file)
htmls.append(html)
try: output_file = 'D:/gzh2/{}_的原创文章_第【{}-{}】篇.pdf'.format(self.gzh_name, (self.index_part - 1) * self.part_offset + 1,self.index_part * self.part_offset)if not os.path.exists(output_file): # 过滤掉重复文件 pdfkit.from_file(htmls, output_file, configuration=self.config, ) # 注意这里需要配置一下wkhtmltopdf except Exception as e:print(sys._getframe().f_code.co_name)print(e)finally:






