2019
年
10
月
18
日希望组面向全球释放三代测序数据高效纠错、组装软件
NextDenovo
最新版本
V2.0-beta.1
(
https://github.com/Nextomics/Next
Denovo
),并免费
开放
用于学术和其他非商业用途。
本次希望组发布的最新版本
NextDenovo
是专为三代测序数据开发的纠错、组装软件,不但解决了现有三代测序数据组装工具资源占用大、运行时间长、组装质量不稳定的瓶颈,还实现了单
Contig
一条染色体和超大型基因组组装的突破,为利用三代数据组装基因组扫清了组装算法的障碍!
图
1 NextDenovo V2.0-beta.1
上线
Github
三代测序数据组装已经成为基因组
De novo
的主流方案,其中
Nanopore
的读长可达数百
kb
甚至超过
2Mb
,在解决染色体着丝粒
/
端粒区域、性染色体等基因组复杂区域,以及复杂基因组组装时,与
PacBio
相比具有更大的优势
[1]
。前不久,加州大学圣克鲁斯基因研究所等单位的研究人员正是利用
Nanopore
的
ultra-long reads
成功拼接出了首个人类
X
染色体基因组完成图序列
[2]
。
然而组装算法方面存在较多的瓶颈,使三代测序的优势不能完全发挥,现有三代测序数据组装软件如:
Falcon
[3]
,
Canu[4]
,
Miniasm[5]
,
Wtdbg[6]
等存在以下几类问题:

针对以上问题希望组胡江团队研发出专门用于三代测序数据纠错、组装的软件——
NextDenovo
。其包含
NextCorrect
和
NextGraph
两个模块,依次进行测序数据的高效纠错、组装,在极大减少计算资源和运行时间的情况下,仍然能够组装出高质量基因组。基于
NextDenovo
,希望组已经实现了小基因组物种近完成图和
>10Gb
基因组物种的组装工作。
NextDenovo
原始数据纠错模块可对
PacBio
和
Nanopore
的三代测序原始数据进行纠错。表
1
为
NextDenovo
与现有主流三代测序数据校正工具(
Canu
、
Falcon
和
Racon
[7]
),对不同三代测序平台(
PacBio
和
Nanopore
)数据的纠错性能比较。
NextDenovo
能够在极大减少运行时间的情况下,达到甚至高于与其他软件的纠错精度。
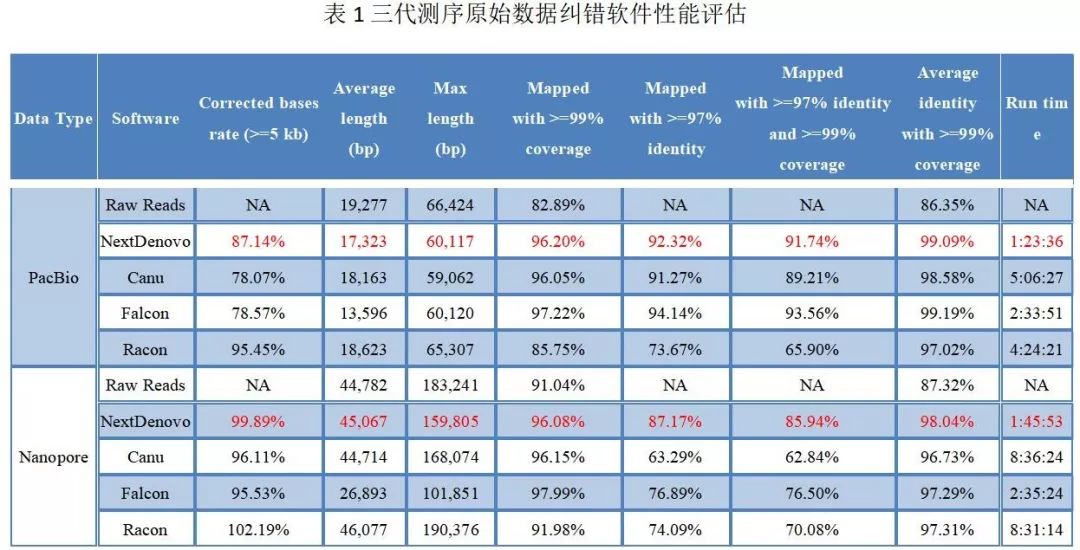
注:
测试数据为人20号染色体PacBio和Nanopore数据各100×,运行环境CentOS Linux release 7.4.1708 (Core),128G内存,32线程(Intel(R) Xeon(R) Gold 6151 [email protected]),参数默认。
NextDenovo
组装模块是基于
String graph
算法,利用纠错后的三代测序数据进行基因组高效组装。
之前的评测结果
表明利用相同的
Nanopore
数据,
NextDenovo
在组装速度、结果连续性等指标均明显优于
Canu
(图
2
)。
Nanopore
数据用
NextDenovo
组装的结果再结合
NextPolish
直接进行
2
轮或多轮二代数据
polish
后,平均碱基准确度能达到
99.99%
以上(关于
NextPolish
的详细评测结果见
https://github.com/Nextomics/NextPolish/blob/master/doc/TEST1.pdf
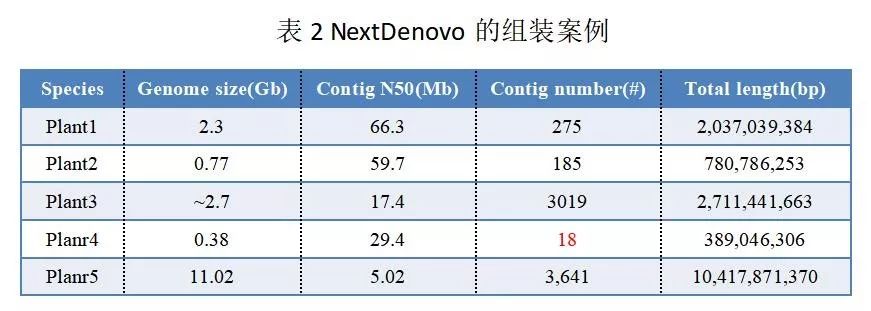
在实际项目应用中
NextDenovo
的表现非常抢眼,某禾本科植物
Plant1
基因组组装
Contig N50
高达
66.3Mb
,某同源多倍体植物
Plant2
的
Contig N50
也达到了
59.7Mb
(表
2
)。与参考基因组比对的共线性图几乎呈一条对角线(图
3
)。
值得一提的是这两个物种基因组都含有大量的
重复序列
,而NextDenovo的组装版本的邻接性要远高于其他版本。
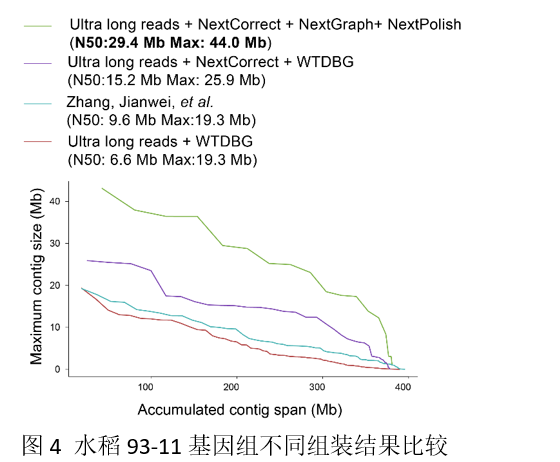
利用
NextDenovo
软件对水稻
93-11
(
Oryza sativa
L. 2n=24
)的
273X
深度
ONT
测序数据进行组装。最终获得的水稻
93-11
基因组仅包含
18
条
Contigs
,
Contig N50
高达
29.43Mb
!
水稻
93-11
基因组的
12
对染色体中,至少有一半的单条染色体由单个
Contig
装出!
BUSCO
评估显示在该组装中可以找到约
98.1%
的完整基因元件,反映组装结果真实可靠。进行基因组单碱基错误率的统计,该组装基因组的单碱基准确率在
99.99%
以上。与其他组装策略相比,利用
Next
系列软件组装的水稻
93-11
基因组质量明显优于其他组装结果
[8]
!
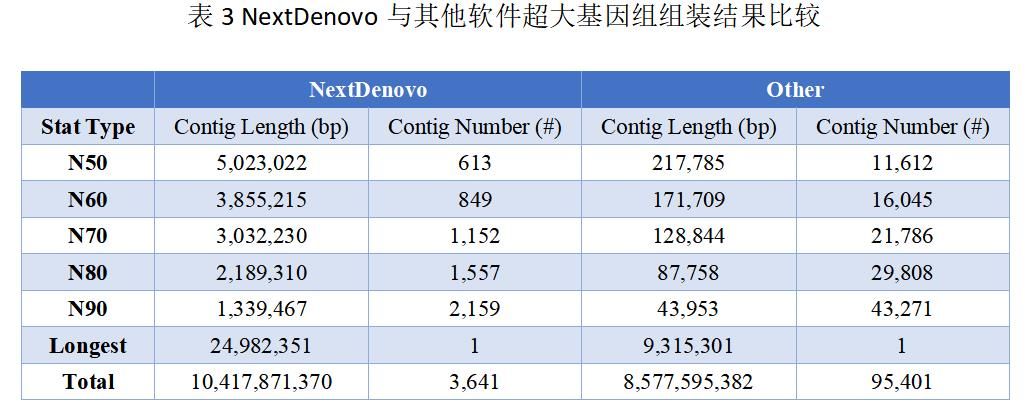
超大型基因组大量高重复区域和动辄
Tb
级别的数据量对组装算法是一个巨大挑战。
NextDenovo
能够很好的处理超大型基因组组装问题,对一个预估基因组
11.02Gb
的超大型基因组进行组装,
NextDenovo
组装版本的基因组与预估大小非常接近约为
10.42Gb
,
Contig N50
达
5.02
Mb
,明显优于常规基因组组装工具(表
3
)。
希望组自成立以来致力于三代测序技术应用与服务,自
2017
年搭建
Oxford Nanopore
测序平台以来陆续开展
ONT Ultra-long
测序、低起始量建库测序等前沿技术研发工作,率先于
2017
年底推出
ONT Ultra-long
测序服务,目前已经完成近百个物种的
ONT Ultra-long
测序、组装工作。公司自主研发的基于
ONT
数据的系列组装、纠错算法软件
NextDenovo
、
NextPolish
,在运行效率、组装质量、适用范围方面均优于现有组装工具,实现了单
Contig
一条染色体和超大型基因组组装的突破。在分析服务方面与华为云合作,将纳米孔测序数据分析流程整合到云计算平台上,实现急速基因组组装与注释,为全球客户提供快速、高效的纳米孔长读长测序计算和存储服务。在三代测序服务领域,希望组技术顶尖,算法领先,服务全面,目前已完成了数百个三代测序科研项目,在
Nature genetics
、
Nature Communications
、
Molecular cell
、
Developmental Cell
等国际权威杂志合作发表多篇研究论文,累积影响因子超过
380
。
[1]
高胜寒
,
禹海英
,
吴双阳
,
等
.
复杂基因组测序技术研究进展
[J].
遗传
, 2018, 40(11): 944-963.
[2]Miga K H, Koren S,Rhie A, etal. Telomere-to-telomere assembly of a complete human Xchromosome[J]. BioRxiv,2019: 735928.
[3]Chin C S, PelusoP, Sedlazeck F J, et al. Phased diploid genome assembly with single-moleculereal-time sequencing[J]. Nature methods, 2016, 13(12): 1050.
[4]Koren S, Walenz BP, Berlin K, et al. Canu: scalable and accurate long-read assembly via adaptivek-mer weighting and repeat separation[J]. Genome research, 2017, 27(5):722-736.
[5]Li H. Minimap andminiasm: fast mapping and de novo assembly for noisy long sequences[J].Bioinformatics, 2016, 32(14): 2103-2110.
[6]Ruan J, Li H.Fast and accurate long-read assembly with wtdbg2[J]. BioRxiv, 2019: 530972.
[7]Sanders A D,Falconer E, Hills M, et al. Single-cell template strand sequencing byStrand-seq enables the characterization of individual homologs[J]. Natureprotocols, 2017, 12(6): 1151.
[8]Zhang J, Chen L L, Xing F, et al. Extensive sequencedivergence between the reference genomes of two elite indica rice varietiesZhenshan 97 and Minghui 63[J]. Proceedings of the National Academy of Sciences,2016, 113(35): E5163-E5171.





