
文 | Google Brain 团队研究软件工程师 Anna Goldie 和 Google Brain 学员 Denny Britz
去年,我们宣布推出 Google 神经机器翻译 (GNMT),这是一个序列到序列(“seq2seq”)的模型,现已用于 Google 翻译生产系统。尽管 GNMT 实现了翻译质量的巨大飞跃,但由于不向外部研究人员提供用于训练这些模型的框架,因此其作用受到影响。
现在,我们很高兴地宣布引入 tf-seq2seq,它是 TensorFlow 中的一个开放源代码的 seq2seq 框架,能简化 seq2seq 模型的试验,获得准确的结果。为此,我们对 tf-seq2seq 代码库进行了清理和模块化处理,从而维持最大的测试覆盖范围,并记录其所有功能。
我们的框架支持标准 seq2seq 模型的各种配置,例如编码器/解码器深度、注意力机制、RNN 细胞类型或集束大小等。正如我们在论文《神经机器翻译架构大探索》(Massive Exploration of Neural Machine Translation Architectures) 中所述,这种多用性让我们得以发现最优的超参数,并在性能上超越其他框架。
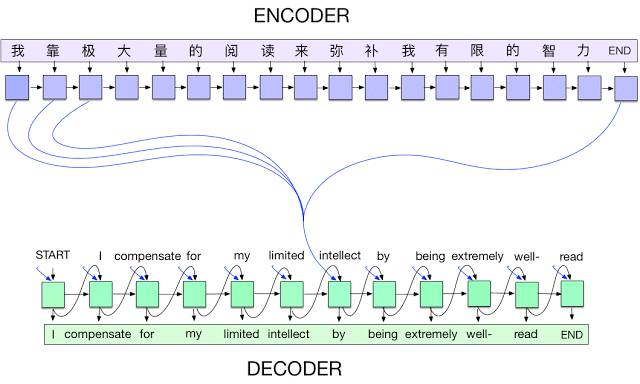
▲
中译英 seq2seq 翻译模型。在每个时步,编码器接收一个中文字符及其之前的状态(黑色箭头),然后生成输出矢量(蓝色箭头)。然后,解码器逐字生成英语翻译,具体步骤是:在每个时步,解码器接收上一个字词及其之前的状态,并对编码器的所有输出(亦称作注意力 [3],用蓝色标示)进行加权组合,然后生成下一个英语单词。请注意,在实现过程中,我们使用词块 [4] 处理生僻词。
除了机器翻译外,tf-seq2seq 还可以用于执行其他任何序列到序列的任务(即,学习在给定输入序列条件下生成输出序列),包括机器翻译汇总、图像字幕制作、语音识别和对话建模等。我们对框架进行了精心设计,以维持此种程度的通用性,并为机器翻译提供教程、预处理的数据和其他实用工具。
我们希望,您能使用 tf-seq2seq 加速(或开始)自己的深度学习研究。我们也非常欢迎您在我们的 GitHub 存储区投稿,在这里,我们发布了各种等待解决的问题,我们希望您能提供协助!
致谢:
非常感谢 Eugene Brevdo、Melody Guan、Lukasz Kaiser、Quoc V. Le、Thang Luong 和 Chris Olah 的大力支持。要深入研究 seq2seq 模型的工作原理,请参阅下面的资源。
参考文献:
[1] 《神经机器翻译架构大探索》(Massive Exploration of Neural Machine Translation Architectures),由 Denny Britz、Anna Goldie、Minh-Thang Luong 和 Quoc Le 合著
[2] 《利用神经网络实现序列到序列的学习》(Sequence to Sequence Learning with Neural Networks),由 Ilya Sutskever、Oriol Vinyals 和 Quoc V. Le 合著。2014 年发表于 NIPS 大会
[3] 《通过联合学习对齐和翻译进行神经机器翻译》(Neural Machine Translation by Jointly Learning to Align and Translate),由 Dzmitry Bahdanau、Kyunghyun Cho 和 Yoshua Bengio 合著。2015 年发表于 ICLR 大会
[4] 《Google 的神经机器翻译体系:缩小机器翻译与人类翻译之间的差距》(Bridging the Gap between Human and Machine Translation),由 Yonghui Wu、Mike Schuster、Zhifeng Chen、Quoc V. Le、Mohammad Norouzi、Wolfgang Macherey、Maxim Krikun、Yuan Cao、Qin Gao、Klaus Macherey、Jeff Klingner、Apurva Shah、Melvin Johnson、Xiaobing Liu、Łukasz Kaiser, Stephan Gouws、Yoshikiyo Kato、Taku Kudo、Hideto Kazawa、Keith Stevens、George Kurian、Nishant Patil、Wei Wang、Cliff Young, Jason Smith、Jason Riesa、Alex Rudnick、Oriol Vinyals、Greg Corrado、Macduff Hughes 和 Jeffrey Dean 合著。2016 年发表于《技术报告》
[5] 《注意力和增强递归神经网络》(Attention and Augmented Recurrent Neural Networks),由 Chris Olah 和 Shan Carter 合著。2016 年发表于《Distill》









