QTLseqr是一个用于BSA-seq的R包,它能够读取GATK输出结果进行过滤,最终使用SNP-index和G 统计值的方法进行定位。我们这次尝试使用这个R包来替代我们自己手撸代码来分析一批水稻BSA数据,文章的数据可以在
生信媛后台
回复"BSA",获取下载链接。
首先是安装和加载R包,由于QTLseqr目前托管在GitHub上,因此需要用devtools才能安装。
devtools::install_github("bmansfeld/QTLseqr")
library("QTLseqr")
在读取数据上,QTLseqr提供了两个函数,importFromGATK和importFromTable,而且这两个函数都没有设置亲本样本名的参数,只有highBulk和lowBulk设置两个混池的样本名。这就很尴尬了,因为我发现直接用
importFromGATK
读取有4个样本的VCF文件会报错。
不过没关系,我们先将数据预处理成
importFromTable
能够识别的格式,就可以进行读取了。
我们先用vcfR提取所需要的信息列,包括AD和GT,前者是等位基因深度,后者是基因型
library(vcfR)
vcf
chrom
pos
ref
alt
ad
ad_split
gt
之后构建数据框, 过滤亲本杂合的位点,并保存到本地
df POS = pos,
REF = ref,
ALT = alt,
AD_REF.SRR6327817 = ad_split[,1],
AD_ALT.SRR6327817 = ad_split[,2],
AD_REF.SRR6327818 = ad_split[,3],
AD_ALT.SRR6327818 = ad_split[,4]
)
mask gt[,"SRR6327815"] != "0/1" & gt[,"SRR6327816"] == "0/1")
df write.table(df, file = "rice.tsv", sep = "\t", row.names = F, quote = F)
之后用
importFromTable
读取,并过滤掉SNPindex为NaN的行
df "rice.tsv",
highBulk = "SRR6327817",
lowBulk = "SRR6327818",
chromList = paste0("chr", formatC(1:12, width = 2, flag=0)),
sep = "\t")
df is.na(SNPindex.LOW) & !is.na(SNPindex.HIGH))
分别运行两种BSA的分析方法,windowSize指的是窗口大小
df
windowSize = 1e6,
outlierFilter = "deltaSNP")
df
windowSize = 1e6,
popStruc = "RIL",
bulkSize = c(20,20))
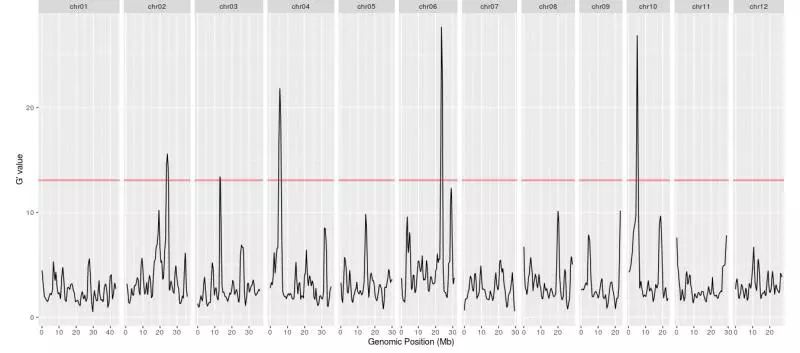
最后我们可视化结果
plotQTLStats(
SNPset = df,
var = "Gprime",
plotThreshold = TRUE,
q = 0.01
)
plotQTLStats(
SNPset = df,
var = "deltaSNP",
plotIntervals = TRUE)

结果和文章比较吻合。
QTLseqr这个R包整体的表现还是可以的,就是对输入有一定的要求,如果直接提供VCF文件需要保证你的VCF文件只有两个样本。也就是你需要先单独对亲本做变异检测,然后用这些位点对两个混池变异检测结果进行过滤,不然这两个亲本的简直就体现不出来了。
推荐阅读
我就是Super Star——基因定位之BSA
以水稻为例教你如何使用BSA方法进行遗传定位(上篇)
以水稻为例教你如何使用BSA方法进行遗传定位(中篇)





