近日改名为 NeurIPS 的原 NIPS 会议将于当地时间 12 月 2-8 日在加拿大蒙特利尔举办。周志华领导的南京大学计算机软件新技术国家重点实验室有多篇论文入选,比如机器之心之前介绍的《NIPS 2018 | 南大周志华等人提出无组织恶意攻击检测算法 UMA》,今天介绍的这篇论文则提出了一种可用于动态环境的自适应在线学习方法。
引言
在线
凸优化
(OCO)已经成为了一种用于建模各种真实世界问题的常用学习框架,比如在线路由、搜索引擎的广告选择和垃圾信息过滤 [Hazan, 2016]。OCO 的协议如下:在第 t 次迭代,
在线学习
器从凸集 X 选择 x_t。在学习器确认这个选择之后,会揭示出一个凸成本函数
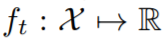
然后,学习器会遭受一个即时的损失
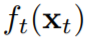
其目标是最小化在 T 次迭代上的累积损失。OCO 的标准性能度量是后悔值(regret):

这是学习器的累积损失减去事后选择的最佳恒定点。
后悔值的概念已经得到过广泛的研究,现在也有很多用于最小化后悔值的算法和理论 [Shalev-Shwartz et al., 2007, Hazan et al., 2007, Srebro et al., 2010, Duchi et al., 2011, Shalev-Shwartz, 2011, Zhang et al., 2013]。但是,当环境会变化时,传统的后悔值不再是合适的度量,因为它是将学习器与一个静态点进行比较。为了解决这一局限性,
在线学习
领域的一些近期进展引入了一种增强的度量——动态后悔值,这方面多年来得到了相当多的研究关注 [Hall and Willett, 2013, Jadbabaie et al., 2015, Mokhtari et al., 2016, Yang et al., 2016, Zhang et al., 2017]。
文献中的动态后悔值有两种形式。Zinkevich [2003] 提出的是一种通用形式,即比较学习器的累积损失与任意比较器(comparator)的序列:
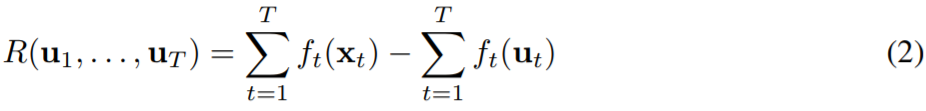
其中 u_1...u_T ∈ X。而大多数有关动态后悔值的已有研究则不同于 (2) 的定义,而是有限定的形式,其中比较器的序列由在线函数的局部最小化器构成 [Besbes et al., 2015],即:
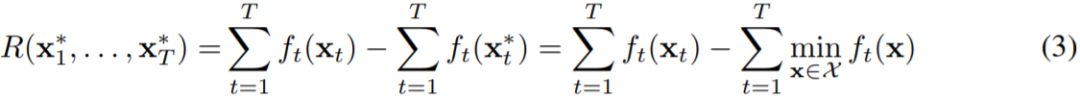
其中

是
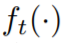
在域 X 上的最小化器。注意,尽管
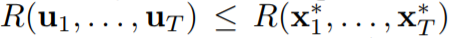
,但并不意味着
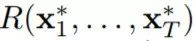
更强,因为对于

的

的上界可能非常宽松。
(2) 中的通用型动态后悔值包含 (1) 中的静态后悔值以及 (3) 中的有限定的动态后悔值特例。因此,最小化通用动态后悔值可以自动适应环境的本质——不管是静态的还是动态的。相对而言,受限的动态后悔值太过悲观,无法适用于静态问题。比如,对于静态
机器学习
问题而言,这是无意义的;在这样的问题中 f_t 是从同一分布中独立采样的。由于采样所造成的随机扰动,预期损失的局部最小化器可能会与全局最小化器有显著的差异。在这个案例中,最小化 (3) 会导致
过拟合
。
因为通用动态后悔值很灵活,所以也是本论文关注的重点。限定通用动态后悔值的范围是非常有难度的,因为我们需要普适地保证其对任何比较器序列而言都成立。通过比较,在限定受限动态后悔值的范围时,我们仅需要关注局部最小化器。到目前为止,我们对通用动态后悔值的了解还很有限。Zinkevich [2003] 给出了一个结果,其证明在线
梯度下降
(OGD)能实现以下的动态后悔值范围。
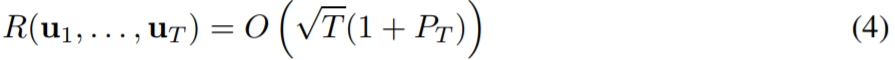
其中 P_T 在 (5) 中定义,是 u_1...u_T 的路径长度。
但是,(4) 中对 P_T 的线性依赖太过宽松,而且在上界和本论文确立的
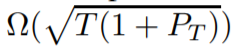
下界之间存在很大的范围。为了解决这一限制,我们提出了一种全新的在线方法,即用于动态环境的
自适应学习
(Ader),其获得的动态后悔值为
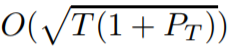
。Ader 遵循带有专家建议的学习框架 [Cesa-Bianchi and Lugosi, 2006],而且受到了 MetaGrad 中维持多个
学习率
的策略的启发 [van Erven and Koolen, 2016]。其基本思想是并行地运行多个 OGD 算法,其中每个算法都有不同的步长,这些步长对特定的路径长度而言是最优的;并将它们与一个专家跟踪算法结合到一起。尽管基础版的 Ader 在每一轮中都需要
查询
梯度
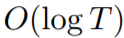
次,但我们还开发了一个改进版,其基于替代损失(surrogate loss)并将梯度评估的次数降为了 1。最后,我们还将 Ader 进行了延展,可用于给出了动态模型的序列的情况;并且当比较器序列紧密遵循这些动态模型时能获得更严格的范围。
本论文的贡献总结如下:
-
我们首次为 (2) 中的通用后悔值范围确立了下界,即
-
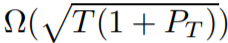
-
我们为最小化通用动态后悔值开发了一系列全新方法,并证明了一个最优的
上界。
-
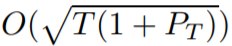
-
相比于 (3) 中已有的受限动态后悔值研究工作,我们的结果是普适的,也就是说后悔值范围适用于任意比较器序列。
-
我们的结果也能自适应,因为其上界取决于比较器序列的路径长度,所以当比较器变化缓慢时它会自动变小。
论文:
动态环境中的自适应
在线学习
(Adaptive Online Learning in Dynamic Environments)

论文地址:
https://arxiv.org/pdf/1810.10815.pdf
在这篇论文中,我们研究了动态环境中的在线
凸优化
,目标是针对任意比较器序列限定动态后悔值的范围。已有的研究已经表明在线
梯度下降
具有
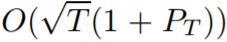
的动态后悔值,其中 T 是迭代次数,P_T 是比较器序列的路径长度。但是,这个结果并不令人满意,因为离本论文确立的
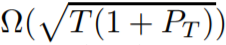
下界存在较大差距。为了解决这一限制,我们开发了一种全新的在线方法,即用于动态环境的
自适应学习
(Ader),其能得到最优的
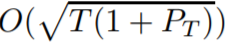
动态后悔值。其基本思想是维持一组专家,其中每个专家都为特定的路径长度求取一个最优动态后悔值,然后使用一个专家跟踪算法将它们组合起来。此外,我们还基于替代损失提出了一种改进版 Ader,使用这种方法,每一轮的梯度评估次数将从 O(log T ) 降至 1。最后,我们还将 Ader 延展到了可使用动态模型的序列来特征化比较器的案例上
。










