300 + 明星创业公司,3000 + 行业人士齐聚
全球人工智能与机器人峰会 GAIR 2017
,一 同见证 AI 浪潮之巅!峰会抢票火热进行中。
今天特放出
直减 700 元的无条件优惠码
(见文末,优惠幅度逐天减小),感谢各位读者对雷锋网的支持,打开链接即可使用。
近日谷歌团队发布了一篇关于语音识别的在线序列到序列模型,该模型可以实现在线实时的语音识别功能,并且对来自不同扬声器的声音具有识别功能。
以下内容是 AI 科技评论根据论文内容进行的部分编译。
论文摘要:生成模型一直是语音识别的主要方法。然而,这些模型的成功依赖于难以被非职业者使用的复杂方法。最近,深入学习方面的最新创新已经产生了一种替代的识别模型,称为序列到序列模型。这种模型几乎可以匹配最先进的生成模型的准确性。该模型在机器翻译,语音识别,图像标题生成等方面取得了相当大的经验成果。尽管这些模型易于训练,因为它们可以在一个步骤中端对端进行培训,但它们在实践中具有限制,即只能用于离线识别。这是因为该模型要求在一段话开始时就可以使用输入序列的整体,这对实时语音识别等任务来说是没有任何意义的。
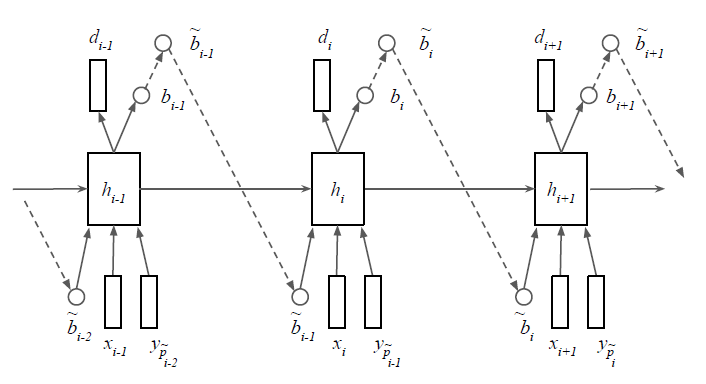
图. 1:本文使用的模型的总体架构
为了解决这个问题,谷歌团队最近引入了在线序列模型。这种在线序列模型具有将产生的输出作为输入的属性,同时还可以保留序列到序列模型的因果性质。这些模型,如序列到序列是因果关系 - 模型在任何时间t产生的输出将会影响随后计算的特征。该模型使用二进制随机变量来选择产生输出的时间步长。该团队将这个模型称为神经自回归传感器(NAT)。随机变量用策略梯度法进行训练。使用修改的培训方法来提高培训结果。

图. 2:熵正则化对排放位置的影响。 每行显示为输入示例的发射预测,每个符号表示3个输入时间步长。 'x'表示模型选择在时间步长发出输出,而“ - ”则表示相反的情况。 顶线 - 没有熵惩罚,模型在输入的开始或结束时发出符号,并且无法获得有意义的梯度来学习模型。 中线 – 使用熵正规化,该模型及时避免了聚类排放预测,并学习有意义地扩散排放和学习模型。 底线 - 使用KL发散规则排放概率,同时也可以缓解聚类问题,尽管不如熵正则化那样有效。
通过估计目标序列相对于模型参数的对数概率的梯度来训练该模型。 虽然这个模型并不完全可微的,因为它使用不可差分的二进制随机单元,但可以通过使用策略梯度法来估计关于模型参数的梯度。更详细地说,通过使用监督学习来训练网络进行正确的输出预测,并加强学习以训练网络来决定何时发出各种输出。
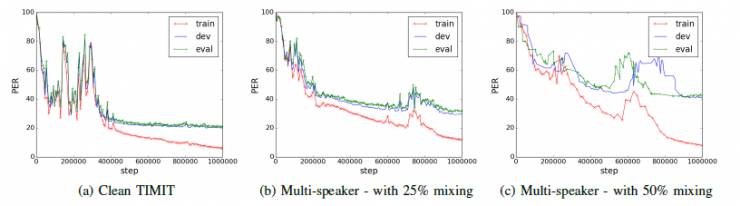
图. 3:在TIMIT上运行示例培训
图3b和3c分别示出了混合比例分别为0.25和0.5的两种情况的训练曲线的实例。 在这两种情况下,都可以看出,该模型学习了过适合数据。
谷歌团队还研究使用该模型进行噪声输入,其中以不同混合比例将两个扬声器的单声道混合语音作为模型的输入。
实验和结果
使用这个模型对两种不同的语音语料库进行了实验。 对TIMIT进行了初步实验,以评估可能导致模型稳定行为的超参数。 第二组实验是在不同混合比例下从两个不同的扬声器(一个男性和一个女性)混合的语音进行的。 这些实验被称为Multi-TIMIT。
A:TIMIT
TIMIT数据集是音素识别任务,其中必须从输入音频语音推断音素序列。有关训练曲线的示例,请参见图3。 可以看出,在学习有意义的模型之前,该模型需要更多的更新(> 100K)。 然而,一旦学习开始,即使模型受到策略梯度的训练,实现了稳定的过程。
表I显示了通过这种方法与其他更成熟的模型对TIMIT实现的结果。 可以看出,该模型与其他单向模型比较,如CTC,DNN-HMM等。如果结合更复杂的功能,如卷积模型应该可以产生更好的结果。 此外,该模型具有吸收语言模型的能力,因此,应该比基于CTC和DNNHMM的模型更适合于端到端的培训,该模型不能固有地捕获语言模型。

表I:针对各种模型使用单向LSTM的TIMIT结果
B:Multi-TIMIT
通过从原始TIMIT数据混合男性声音和女性声音来生成新的数据集。 原始TIMIT数据对中的每个发音都有来自相反性别的发声。
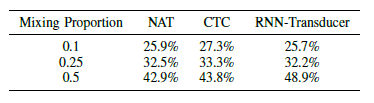
表II:Multi-TIMIT的结果:该表显示了该模型在不同比例的混合中为干扰语音所实现的音素误差率(PER)。 还显示了深层LSTM 和RNN-自感器 的CTC的结果
表II显示了使用混合扬声器的不同混合比例的结果。 可以看出,随着混合比例的增加,模型的结果越来越糟糕。 对于实验,每个音频输入始终与相同的混音音频输入配对。 有趣的是,可以发现,将相同的音频与多个混淆的音频输入配对产生更差的结果,这是由于产生了更为糟糕的过度配对。 这可能是因为该模型强大到足以记住整个翻译结果。
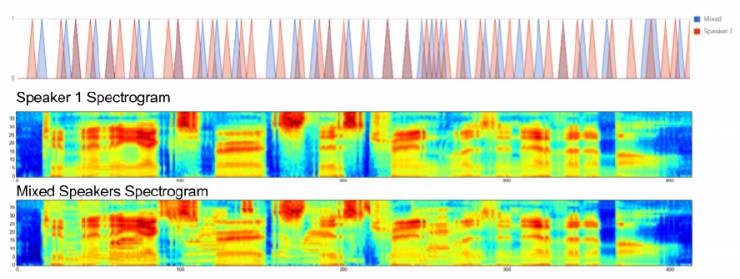
图. 5:Multi-TIMIT的声音分布:该图显示了在TIMIT中发出干净话语的情况下发出令牌的概率以及Multi-TIMIT中对应的噪声发音。 可以看出,对于Multi-TIMIT语句,该模型稍稍比TIMIT语句发出符号要晚一点。
图5显示了为示例Multi-TIMIT话语的模型发出符号的。 它还显示了与一个干净模型的发出进行比较。 一般来说,与TIMIT发出的模型相比,该模型选择稍后再发布Multi-TIMIT。
结论:在本文中,谷歌团队引入了一种新的在线序列到序列模型的训练方式,并将其应用于嘈杂的输入。 作为因果模型的结果,这些模型可以结合语言模型,并且还可以为相同的音频输入生成多个不同的成绩单。 这使它成为一个非常强大的类型的模型。 即使在与TIMIT一样小的数据集上,该模型能够适应混合语音。 从实验分析的角度来说,每个扬声器只耦合到一个干扰扬声器,因此数据集的大小是有限的。 通过将每个扬声器与多个其他扬声器配对,并将每个扬声器预测为输出,应该能够实现更强的鲁棒性。 由于这种能力,该团队希望可以将这些模型应用到未来的多通道,多扬声器识别中。
via
Techcrunch
https://gair.leiphone.com/gair/coupon/s/594fb39fb1081
优惠券仅限「参会门票」。
赠送的优惠劵额度每天递减 50 元,有效期为 1 天,可供多人使用。
长按复制链接在浏览器打开,或
点击文末
阅读原文
立即使用。
AI科技评论招人啦!
作为国内顶尖人工智能学术媒体,AI科技评论一直秉承“洞悉学术前沿,连结产业未来”的理念,为读者奉上来自国内外的深度报道。
AI科技评论期待你的加入,和我们一起见证未来!现诚招学术主编(外聘)、学术编辑、外翻编辑等岗位,详情请
点这里
欢迎投递简历到:[email protected],AI 科技评论等你哦!






